
티스토리 뷰
Lv3 - 5~6주차 미션 : JDBC 구현, 대용량 데이터 처리
https://github.com/woowacourse/jwp-jdbc
학습목표
- 나만의 라이브러리를 구현하는 경험을 함으로써 중복을 제거하는 연습을 한다.
- 기존 코드를 깨트리지 않으면서 리팩토링하는 연습을 한다.
- 목표로하는 결과를 얻기 위한 SQL 쿼리를 작성할 수 있어야 한다.
- SQL 쿼리의 실행 계획을 볼 수 있어야 하며, 성능상 문제가 되는 부분을 찾을 수 있어야 한다.
- 대용량 데이터에 대해 목표로하는 성능을 낼 수 있도록 튜닝할 수 있어야 한다.
요구사항
- Jdbc 라이브러리를 구현해서, UserDao엔 개발자가 작성해야하는 코드만 남기자

- 리팩토링 과정에서 컴파일 에러를 내지 않기 "점진적인 리팩토링"
- 메소드2를 추가해서 해결가능한 작업과 클래스를 새로 추가해야하는 작업을 구분할수있어야함
- 리팩토링 과정 중간중간의 각 커밋 시점에서도 컴파일&빌드 및 기능이 정상적으로 작동하도록, 해야한다고 생각하니 좀더 이해가 됬다
- 즉, 기존의 코드와 리팩토링 코드가 공존하는 환경
- Docker를 활용해 MySQL 설치
- 현재 DB 연결을 위한 설정을 소스코드에서 하드코딩 하고있는데, 이를 db.properties 파일로 분리
- 대용량 데이터를 import하고 요구사항을 만족
- (필수) 1단계 : assert문을 이용하여 결과값을 테스트한다.
- (Advanced) 2단계 : assertTimeout 활용하여 100ms 이하로 결과를 반환한다.
키워드
Spring Jdbc- Spring의 JdbcTemplate에서도 사용하는
PreparedStatementSetter와RowMapper - 좀더 구체적인 개념들
- 가변 인자와 RowMapper
- try-with-resources문
- SQLException 처리
- callback interface/functional interface, Generic
- 익명 클래스 -> Java8 Lambda
- 대용량 데이터 처리 미션
- 쿼리 최적화
- DB Optimizer
- 인덱스
- Docker
- 실행 계획
느낀점
- 미션을 진행하며, 토비 스프링 3장의 '초난감 JDBC'부터 Spring Jdbc까지 리팩토링하는 과정 & 레벨1 체스 미션에서 JdbcTemplate 클래스를 만들었던 과정이 기억났음
- 라이브러리와 개발자의 역할 분리나 UserDao에서 차근차근 JdbcTemplate으로 분리해나가는 과정은, 위에서 이미 경험하고 알고있던 부분이 많아서 다른 미션에 비해 상대적으로 수월하고 익숙했다.
- 다만 컴파일 에러를 내지않고, 점진적인 리팩토링하는 연습은 계속해서 연습해야겠다 :)
- 인덱스를 처음 써봤는데 무척 효과적이었다. DB의 핵심인만큼 그 원리와 관련 개념을 학습해야겠다.
- 도커도 처음 써봤는데 흥미로웠다. 좀더 제대로 알아봐야겠다.
- 쿼리 최적화, 튜닝과 관련해 다음의 책을 읽어보자.
- [SQL 레벨업]
- [SQL 코딩의 기술]
- [데이터베이스를 지탱하는 기술]
내 코드, 피드백 관련

- JdbcTemplate에서의 트랜잭션 관리와 관련하여
- 미션 진행과정에서 페어와 함께 "메소드 실행 중간에 exception이 발생하면 롤백시켜야지"라는 부분에 꽂혀서 다음과 같이 트랜잭션 관리를 하려 했다.
- 하지만 다시 생각해보니, select문같은건 롤백이 필요없을 뿐만 아니라, executeQuery, query, queryForObject 세 메소드 모두 pstmt.executeQuery() 작업이 한번만 일어난다.
- 즉 JdbcTemplate에서 별도의 트랜잭션 관리를 해줄 필욘 없었고, 나중에 서비스 계층에서 mutiple insert가 일어난다면 그런곳에서 해주는게 맞다고 생각하게 되었다.
- 다음 DI미션의 Adv로 @Transactional 구현이 있던데, 그때 만들어볼수있다면 좋을것 :)
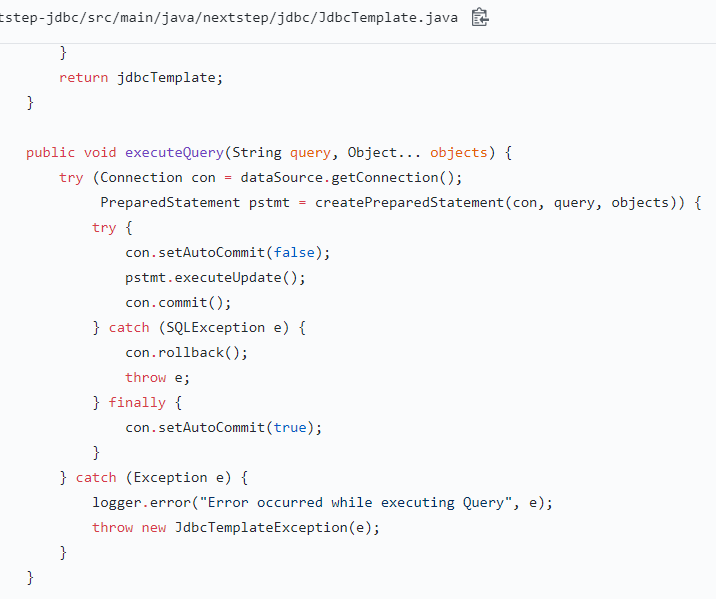
- Reflection vs RowMapper (JdbcTemplate에서 ResultSet으로부터 UserDao에게 유저 객체를 만들어주는 방법)
- RowMapper를 이용한 방식외에, 리플랙션을 이용해도 좋을 것같아서 2가지 방법으로 미션을 구현하고 제출해봤다. 리플랙션을 이용해 JdbcTemplate을 구현했더니, 라이브러리 사용자인 UserDao측에선 단순히 User.class만 인자로 넘기면 객체를 받을 수 있었기 때문이다.
- 이후에 고민해보니, 리플랙션을 사용하면 객체를 생성하는 방식이 획일화(모든 필드를 긁어와 초기화)되어서 유연성이 떨어질것같았다. (예를 들어, 필드와 생성자가 여러개인 경우 오류 발생 가능) 따라서 UserDao가 방법을 정하도록 하는게 나을것같았다.

- 가변인자 vs PreparedStatementSetter (UserDao에서 JdbcTemplate의 메소드로 쿼리문에 set할 인자들을 보내는 방식)
- 가변인자로 처리했다가, 처음엔 PreparedStatementSetter의 필요성과 이점을 굳이 느끼지 못했다. 기존의 JdbcTemplate에 있는 `createPreparedStatement` private메소드를 클래스로 분리하는것뿐이라 생각했기 때문이다.
- 역시 좀더 생각해보니, 라이브러리를 사용할때 SQL문에 들어가는 값의 개수와 순서가 중요한 부분인데, 해당 클래스를 사용하면 좀더 이부분을 명시적으로 할 수 있을것 같았다.
- 기존처럼 pstmt에 set하는 부분을 JdbcTemplate에서 내부적으로 처리하면, 인자 순서를 잘못보내도 세팅되버린다. 하지만 다음과 같이 이부분을 UserDao가 책임지게하면 좀더 안정적으로 변한다. 또한 pstmt.setString()같은 메소드를 사용한다면 타입도 명시할 수 있다.
- 하지만, 가변인자 방식도 UserDao가 사용하는 입장에선 코드가 간결하다. 방식마다 장단점이 있고, 라이브러리 입장에선 오버로딩을 통해 사용자에게 다양한 방식을 제공하면 좋을것 같다.


- Spring의 Singleton과 Java Static기반 Singleton pattern의 차이
- 포비가 지나가다 툭 던져주신 한마디로 고민해볼거리가 생겼다. 나는 기존에 UserDao를 일반적인 LazyHolder를 이용한 싱글톤 패턴으로 구현해놓았었다. 하지만 스프링에선 맨처음에 인스턴스를 한번만 생성한뒤 이를 계속해서 주입해서 사용하는 방식으로 '싱글 인스턴스'를 보장한다는 점을 지적해주셨다.
- 현재의 코드에서 스프링 방식으로 싱글 인스턴스를 보장하는 방법을 생각해봤더니, 컨트롤러를 생성할때 UserDao를 하나 만들어서 이를 주입해주는 방법이 떠올랐다. (ManualHandlerMapping#initialize) 또는 `@Autowired` 어노테이션을 만드는 방법도 있을것같았다.
- 이부분은 다음미션에서 경험해볼 수 있을 것 같다 :)
- 참고로, 내가 느낀 싱글 인스턴스를 보장해주는 방법에 있어서 static방식보다 스프링의 주입방식이 좀더 나은 이유는 - 주입이 getInstance를 통한 객체획득보다 테스트가 쉽고 & 위의 링크에서 언급된대로 static방식은 다른 서블릿간에 같은 인스턴스가 참조되어 sideEffect가 생길수있을것(?)으로 생각했기 때문이다.

- null대신 Optional을 리턴하도록 수정했다

대용량 데이터 처리 미션
- 성능 최적화
- 대부분의 성능 이슈는 애플리케이션 코드보다, SQL 쿼리와 외부 API를 콜할 때 발생한다.
- 애플리케이션 코드는 성능 차이가 큰게 아니면 가독성을 우선한다.
- 반면, 쿼리문은 일반적으로 성능 차이가 커서 튜닝을 통해 최적화한다.
- 강의자료와 CU코치자료를 통해 학습하자.
- 특히 인덱싱&슬로우쿼리 부분 ★
- 다른 모듈을 import해 사용하는 방식도 흥미로웠다.

- 2가지 미션
- 코드
- 첫번째 요구사항 hobby에선 인덱스의 성능을 실감할 수 있었다.
- 관련해서 몇가지 이슈를 경험
- 두번째 요구사항 codingYearsByDevType에선 복잡한 쿼리문을 경험해볼 수 있었다.
- 시간이 부족해 충분한 쿼리 최적화를 고민해보진 못했다.
- 테스트 코드에서 시간을 측정할 때, db와 쿼리 부분 뿐만아니라 단순히 커넥션을 가져올때도 시간이 많이 소모됬다. 만약 DBCP를 만들어서 커넥션 만드는데 걸리는 시간을 줄였으면, getConnection 부분을 좀더 효율적으로 바꿀수있지않았을까싶은 아쉬움
- 이슈1 - 2가지 Column으로 인덱스가 적용되있을때 첫번째 인덱스 컬럼을 쿼리문에서 사용하지 않아도, 인덱스 테이블을 타는가
- 3가지 상황
- Index : X
- Index : hobby
- Index : student, hobby
- 1번은 당연히 Full Table Scan이 실행됬다. 소요시간도 6200ms
- 2번은 idx_hobby에 대해 Full Index Scan이 실행됬다. 쿼리문중에 sum(*)이 있어서 모든 row를 돌아야해서 그랬을것. 소요시간 50ms
- 3번이 문제인데, idx_student_hobby에 대해 Full Index Scan이 실행됬다..?! 소요시간 약 130ms
- https://gywn.net/2013/09/let-me-know-data-searching-in-sqlite/ 같은 일반적인 블로그들엔, 이런 상황에서 인덱스 테이블은 타지만 원하는대로 인덱싱을 수행할수없다고 표현한다.
- 반면, 이동욱님의 블로그에선, 인덱스 테이블 자체를 안탄다고 말씀하신다.
- 직접 확인해봤을땐, 인덱스 테이블을 타긴 탔다. 일단은 인덱스 테이블은 타지만 원하는대로 인덱싱을 수행할 수 없는 것으로 결론. 조조님의 결과와 다른 이유는 환경이 달라서 그럴수도있겠다. 나도 대용량 SQL 파일이 아닌 매우작은 테이블에서 실험해봤을땐 Full Table Scan이 일어날때도 있더라. Optimizer의 영향이 있을수도 ?!
- 3가지 상황
- 이슈2 - hobby 미션은 (%를 구할때 분모 때문에)
count(*)쿼리로 인해 '결국은 테이블의 모든 row를 보게 됬다.' 그런데 이때 왜 인덱스 사용유무에 따라 성능차이가 났을까?- 인덱스를 안쓰면 Full Table Scan, 쓰면 Full Index Scan이 일어난다.
- 하지만
count(*)때문에 결국 모든 row를 방문하게 된다. 그런데 왜 7초 vs 0.?초의 큰 성능차이가 나는 걸까? - Answer : 우리 survey_results_public 테이블을 보면 row뿐만 아니라, column도 매우 많다. Full Table Scan을 하게되면 hobby뿐만아닌 모든 컬럼도 방문하므로 시간이 오래걸리고, Full Index Scan을 하면 rowId를 이용해 해당 hobby 블록에만 방문해서 차이가 난다고 한다.
'우아한 테크코스' 카테고리의 다른 글
| 우아한 테크코스) Lv4 [팀 프로젝트] 정리, 후기 (0) | 2020.01.09 |
|---|---|
| 우아한 테크코스) Lv3 - 7~9주차 [DI 구현] 미션 후기, 코드 리뷰 (0) | 2019.11.16 |
| 우아한 테크코스) Lv3 - 남은 학습주제, 회고 (0) | 2019.10.13 |
| 우아한 테크코스) Lv3 - 3~4주차 [MVC 구현] 미션 후기, 코드 리뷰 (0) | 2019.10.13 |
| 우아한 테크코스) Lv1, 2 - 나에 대한 피드백 정리, 회고 (from 미니프로젝트, 페어프로그래밍) (0) | 2019.10.03 |
댓글
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
TAG
- reversing
- sort
- C
- mysql
- Android
- FRAGMENT
- Java
- Vo
- bfs
- Algorithm
- 해외여행
- OneToMany
- 리버싱
- dfs
- brute-force
- 개발자
- graph
- javascript
- 웹해킹
- queue
- Android Studio
- git
- 회고
- Stack
- JPA
- 프로그래머스
- socket
- webhacking.kr
- 우아한 테크코스
- Data Structure
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
글 보관함